Document's Audience:
- Current H5 library designers and knowledgable external developers.
Background Reading:
- Dataset Chunking in HDF5
- This explains the current state of chunking in HDF5.
Introduction:
- What is this document about?
- This document describes ideas for introducing a new method of efficiently storing raw data for an HDF5 dataset in certain special cases described below.
- What is currently supported?
- Currently we require all chunks for a dataset to have three major
requirements: that they are identical in shape (# of dimensions and
the dimension sizes), they are non-overlapping and they are
"regular" in their shape. "Regular" shaped chunks are essentially
N-dimensional rectilinear blocks. Here's an example of
non-overlapping, identical, regular shaped chunks:
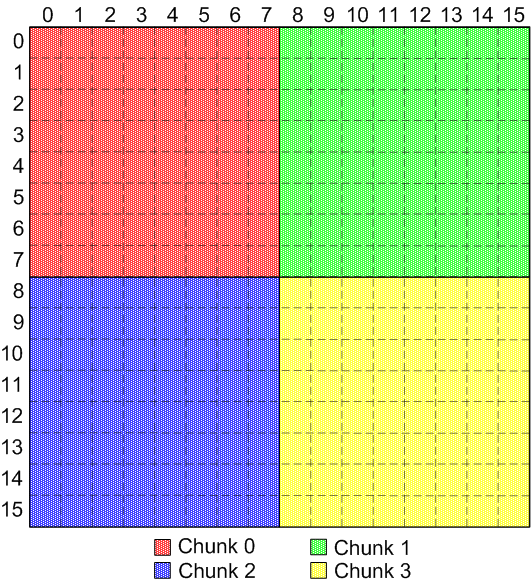
Regular, non-overlapping, identical chunks [Note - Should we expand this support to allow for overlapping regular, identical chunks?]
- What areas do we want to expand chunking support in?
- We would like to expand support for chunked datasets to allow chunks for a dataset to not be all the identical size. Additionally, it would be desirable to support chunks that are irregularly shaped and overlapping other chunks.
- Why do we want to expand chunking support?
- Our customers would like to be able to have different sized pieces of a dataset in different processes and to write out each of those pieces in one I/O operation, see the discussion of Efficient I/O. Additionally they would like to store multiple dataset elements in each coordinate location.
- What are "variable-sized" chunks?
- "Variable-sized" chunks are "regular" shaped chunks that have the
same number of dimensions, but each may have different sizes.
Here's an example of non-overlapping, variable-sized regular chunks:
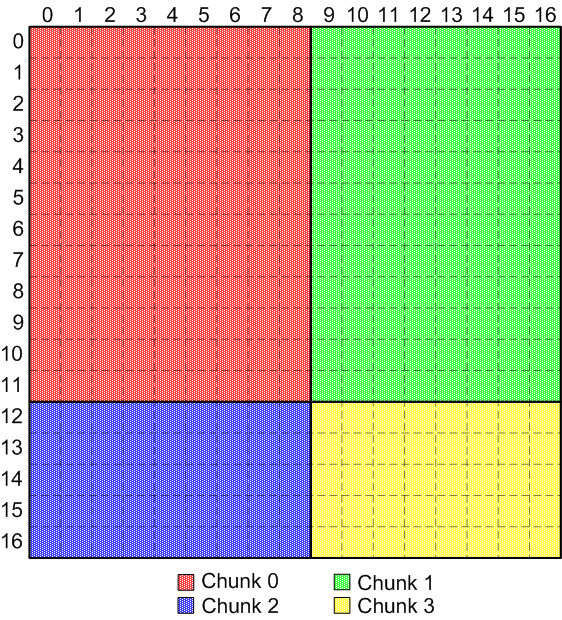
Regular, non-overlapping, variable-sized chunks Here's an example of overlapping, variable-sized, regular chunks:
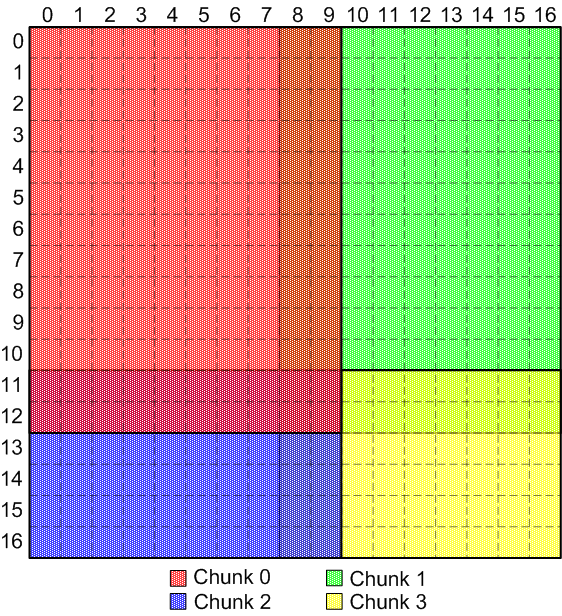
Regular, overlapping, variable-sized chunks - What are "irregular" chunks?
- "Irregular" chunks are chunks that can have any shape, including
holes and discontinuities, although they all still must have the
same number of dimensions. "Irregular" chunks are by definition
"variable-sized" chunks.
Here's an example of non-overlapping, irregular chunks:
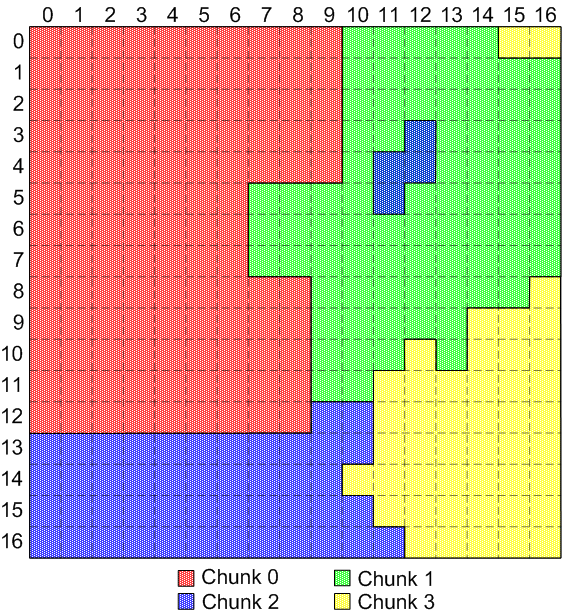
Irregular, non-overlapping chunks Here's an example of overlapping, irregular chunks: (see this page for a view of the individual chunks for this diagram)
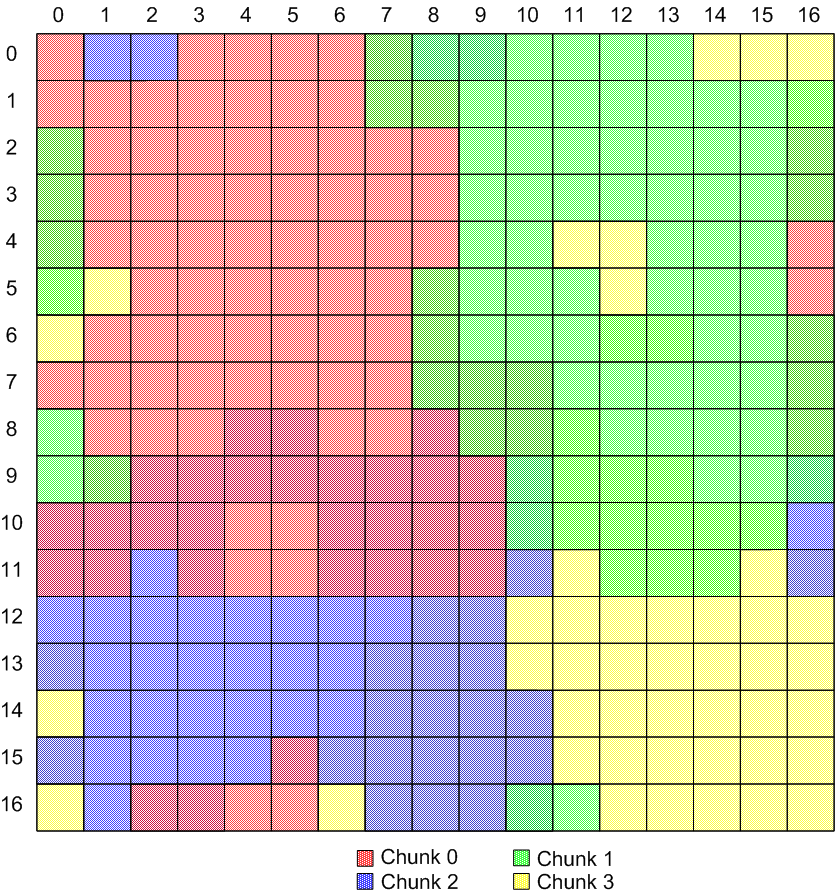
Irregular, overlapping chunks
Use Cases:
The desire to add support for variable-sized (including irregularly shaped) and/or overlapping overlapping chunks comes from a number of use cases. ("client" in all these use cases could be either another library (such as SAF or UDM) or an application)
Dataset creation use case scenarios: (collective)
Dataset I/O use case scenarios: (independent) (these apply equally to reading and writing)
- Differently sized, non-overlapping selections in each process
- Differently sized, overlapping selections in each process
Dataset query use case scenarios: (independent)
Dataset extension use case scenarios: (collective)
Potential Problems:
Clients who have discontiguous variable-sized chunks on disk may find that the library orders their data in suprising ways.
Defining chunks one at a time allows to the possibility that there are elements in the dataset's dataspace which are not covered by any chunks.