Clients desire to have each write operation from a process in a parallel
application perform only one low-level write operation to disk (i.e. only
one call to MPI_File_write_at (or MPI_File_write_at_all). When using chunked
storage for datasets, this can only be done if the data that each process
writes out is exactly aligned with a single chunk.
For example, if the chunks for a dataset are regular and non-overlapping,
and are defined like this:
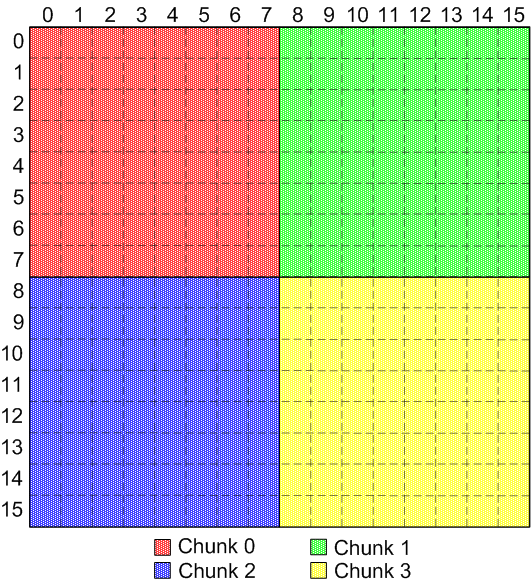
|
Regular, non-overlapping, identical chunks
Each chunk in the dataset is stored contiguously on disk, like this: (note
that the chunks themselves are not necessarily adjacent)
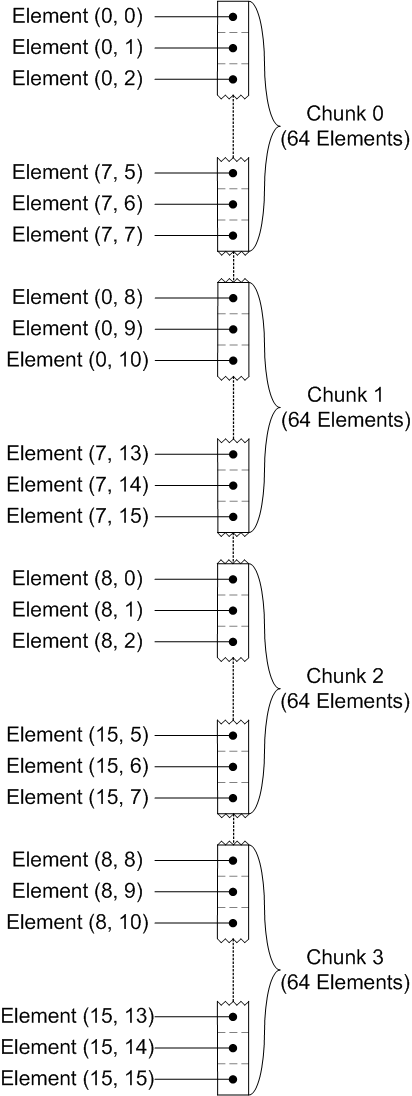
|
Chunk layout on disk
Assume for the purpose of this example, that the size of the datatype for
each element in the dataset is 4 bytes (making each chunk 256 bytes in size)
in the file. Also, assume that the client is using 4 processes
to access the dataset.
The following table describes the hyperslab selection for each client
process:
| Client Process # |
"Start" location |
"End" location |
| 0 |
(0, 0) |
(7, 7) |
| 1 |
(0, 8) |
(7, 15) |
| 2 |
(8, 0) |
(15, 7) |
| 3 |
(8, 8) |
(15, 15) |
This corresponds to each client process's selection exactly aligning with a
chunk in the dataset:
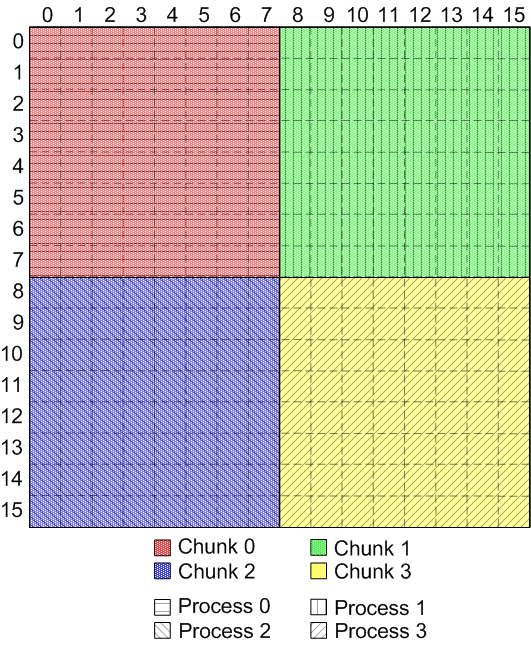
|
Aligned disk selection and chunk layout
When I/O is performed by each client process with these selections and
chunks defined, each process will perform only one I/O operation, as indicated
by the following table:
| Client Process # |
Number of I/O operations |
# of Bytes In Selection |
# of Bytes Transferred |
Byte Transfer Efficiency |
| 0 |
1 |
256 |
256 |
100% |
| 1 |
1 |
256 |
256 |
100% |
| 2 |
1 |
256 |
256 |
100% |
| 3 |
1 |
256 |
256 |
100% |
Now, assume that the following selections have been made:
| Client Process # |
"Start" location |
"End" location |
| 0 |
(0, 0) |
(9, 8) |
| 1 |
(0, 9) |
(6, 15) |
| 2 |
(10, 0) |
(15, 8) |
| 3 |
(7, 9) |
(15, 15) |
These selections are not aligned with the chunks:
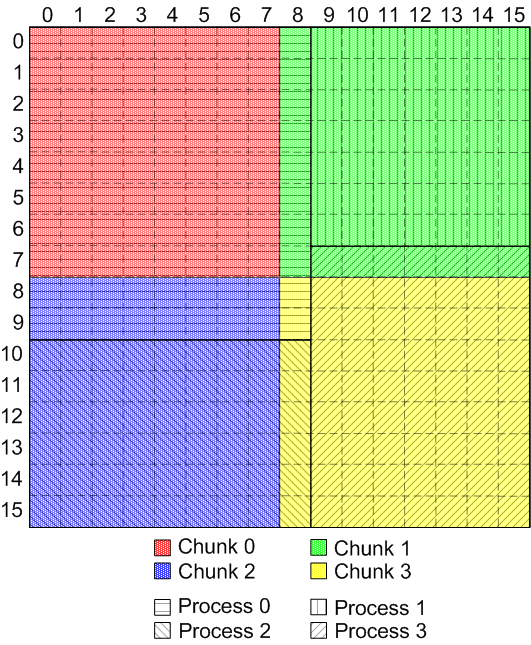
|
Unaligned disk selection and chunk layout
Having mis-aligned file selections and chunks results in a much larger number
of I/O operations and bytes transferred to disk:
| Client Process # |
Number of I/O operations |
# of Bytes In Selection |
# of Bytes Transferred |
Byte Transfer Efficiency |
| 0 |
4 |
360 |
1024 |
35.16% |
| 1 |
1 |
196 |
256 |
76.56% |
| 2 |
2 |
216 |
512 |
42.19% |
| 3 |
2 |
252 |
512 |
49.22% |
However, if chunks are allowed to be variable-sized, they could be defined
like this:
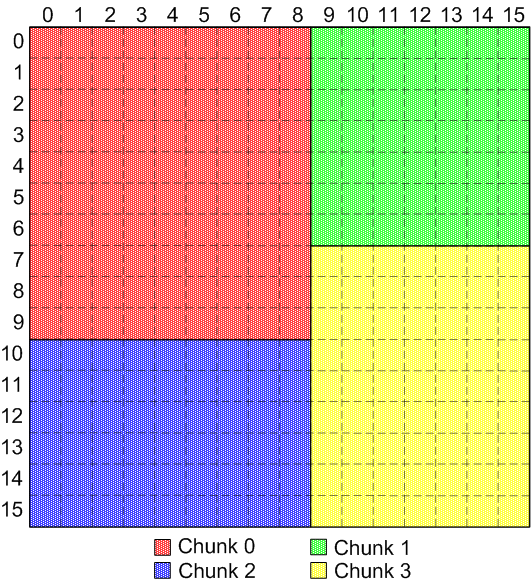
|
Regular, non-overlapping, variable-sized chunks
Each chunk in the dataset is still stored contiguously on disk, like this:
(note that the chunks themselves are not necessarily adjacent)
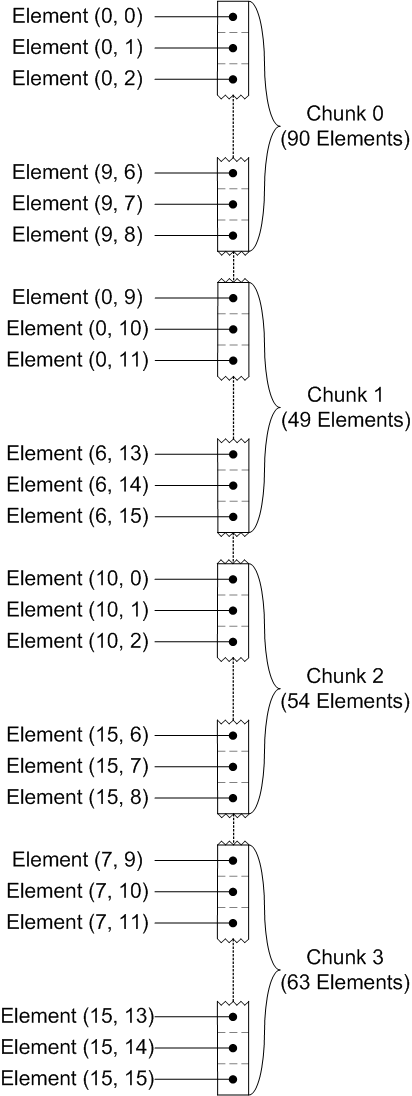
|
Chunk layout on disk
Then, the variable-sized selections for each client process (as defined
above) would be aligned with the chunk boundaries:
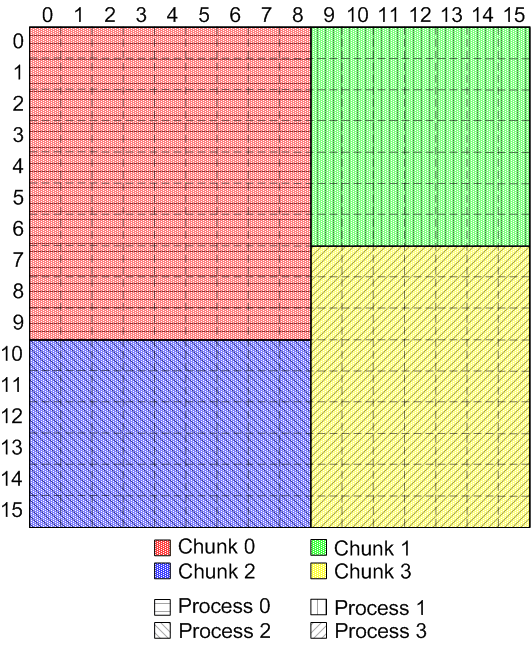
|
Aligned disk selection and chunk layout for variable-sized chunks
And would have the optimal number of I/O operations and bytes transferred
again:
| Client Process # |
Number of I/O operations |
# of Bytes In Selection |
# of Bytes Transferred |
Byte Transfer Efficiency |
| 0 |
1 |
360 |
360 |
100% |
| 1 |
1 |
196 |
196 |
100% |
| 2 |
1 |
216 |
216 |
100% |
| 3 |
1 |
252 |
252 |
100% |