Thread Safe HDF-5
Issues, and an Implementation Plan
HDF5 will support two types of parallel architectures: distributed multi-processors and symmetric multi-processors. The distributed multi-processor support is already partially designed and implemented and builds upon MPI and MPI-IO. This document describes the planned implementation for symmetric multiprocessors using POSIX.1c threads, focusing on issues of thread safety pertaining to the calling of HDF5 API functions from a multi-threaded application. In short, any set of HDF5 functions may be called concurrently without adverse interactions between the functions, and the library will provide a reasonable level of concurrency.
A "thread-safe" version of HDF-5 (TSHDF5) is one that can be called from any thread of a multi-threaded program. Any calls to HDF can be made in any order, and each individual HDF call will perform correctly. A calling program does not have to explicitly lock the HDF library in order to do I/O. Applications programmers may assume that the TSHDF5 guarantees the following:
These properties mean that the TSHDF5 library will not interfere with an application's use of threads. A TSHDF5 library is the same library as regular HDF-5 library, with additional code to synchronize access to the HDF-5 library's internal data structures.
Multi-threading is not completely standardized. There are a number of similar but incompatible thread interfaces. Each provides similar services, but the details may differ. The most popular threading packages are Posix P-threads and NT threads. P-threads is typically implemented as a library, NT threads are part of the operating system.
POSIX.1c threads (IEEE POSIX 1003.1c-1995), also known as the ISO/IEC 945-1:1996 standard, part of the ANSI/IEEE 1003.1 1996 edition, are emerging as the standard multi-threading API on Unix systems. Implementations of the API are already available under Sun Solaris 2.5, Digital Unix 4.0, Silicon Graphics IRIX 6.2, Linux 2.0, and should soon be available from other vendors such as IBM and HP. More generally, the 1003.1c API is quickly replacing proprietary threads libraries that were developed previously under Unix such as Mach cthreads, Solaris threads, and IRIX sprocs. Thus, multithreaded programs using the 1003.1c API are likely to run unchanged on a wide variety of Unix platforms.
DCE threads are based on draft 4 (an early draft) of the POSIX threads standard (which was originally named 1003.4a and became 1003.1c upon standardization) and will likely be replaced by the 1003.1c API. Converting to POSIX.1c threads would require a moderate amount of work.
Unix International (UI) threads, also known as Solaris threads, are based on the Unix International threads standard (a close relative of the POSIX standard). The only major Unix variants that support UI threads are Sun Solaris 2 and SCO UnixWare 2. Porting to POSIX.1c threads would require a moderate amount of work.
The futures for OS/2 threads and Windows NT threads are probably different. Both implementations contain some fairly radical departures from the POSIX standard -- to the degree that even porting from one or the other to POSIX will prove moderately challenging. Neither one plans to adopt the standard. The POSIX-compliant Windows NT does not support threads. [citation?]
The HDF-5 library manages I/O transfers between memory and disk, and copies of the data and metadata may exist on both disk and in memory. When an application calls the HDF-5 library to create, delete, or modify data, changes are made to data structures in memory, and eventually written to disk. A thread safe HDF-5 library must guarantee that each call to the library will have correct results: if one thread creates an object, other threads will be able to access it as soon as the creation completes, and so on.
The HDF-5 library performs I/O, transferring data between memory buffers and disk storage. The TSHDF5 library may be called from any thread of a multi-threaded application, but it does not manage scheduling of threads by a calling program, nor does it do anything to insure thread safety in routines that it calls. These programs and libraries must themselves assure the correctness of the sharing between threads. Some illustrations follow.
Concurrent access to memory. An application program is responsible for managing shared memory buffers. If multiple threads are writing and/or reading to and/or from shared areas of memory, the TSHDF5 itself library can not guarantee that the results will be correct. The application must assure that a result is not read before an HDF-5 "read" completes, that the memory is not modified before the HDF-5 "write" completes, and so on.
Concurrent Access to disk. The HDF-5 library accesses disk storage through the operating system, so for multi-threaded programs the TSHDF5 library provides whatever semantics the operating system provides. Hence, when multiple threads read and write to the same area on disk TSHDF5 does not guarantee consistent results beyond that provided by the OS.. TSHDF5 can guarantee that each read and write will be completed correctly, but the order of completion is unspecified, and might vary from run to run or from platform to platform.
Libraries called by HDF5. TSHDF5 will assume that all libraries called from the HDF5 library are thread-safe. Functions in the C library that are inherently not safe will be replaced with the _r counterpart through the HD wrappers defined in H5private.h. It is an application's responsibility to make sure that other libraries are called in an appropriate manner. For instance, if the MPIO and/or MPI libraries are not MT-safe then the application should not use the MPIO file access driver. It is beyond the scope of the HDF5 configuration to determine when supporting libraries are thread safe.
HDF5 is not interprocess-safe. HDF5 is not interprocess-safe--two processes cannot simultaneously access an HDF5 file--so no attempt is made to prevent deadlocks in HDF5 by resetting state information with pthread_atfork(). Don't call HDF5 functions from a child process.
TSHDF5 Does Not Provide Transactions. TSHDF5 serializes accesses to the library, each API call is atomic. If an application needs a sequence of operations to be atomic (e.g., Read, Modify, Write), the application code must provide the appropriate concurrency protocols.
The TSHDF5 plan includes three levels of concurrency which may be implemented:
A fourth level, which we are not contemplating, involves threading within the library, such as separate locks per pipeline stage.
These are progressively finer interleaving of threads, giving finer grained parallelism within the library, and progressively greater implementation cost. In order to have a deliverable at the earliest possible date, the thread-safety implementation will consist of three steps:
These are progressively finer interleaving of threads, giving finer grained parallelism within the library, with progressively greater implementation cost.
Fortunately, HDF5 was designed with thread safety in mind and the API will require no modifications when used in a multi-threaded program. However, a myriad of tasks must be completed to make HDF5 thread-safe.
Since the thread-safety could introduce unecessary overhead for serial applications and because multi-thread support might not be available, the implementation will be such that thread-safety can be enabled or disabled at configuration time by using configure's --enable-threads or --disable-threads command-line switches which define (or not) the HAVE_PTHREADS preprocessor constant. The HDF5 public header files will be applicable to both thread-safe and -unsafe libraries so only one copy needs to be installed and thread safety can be turned on or off in the application by linking with the appropriate HDF5 library.
The following sections describe the serialization of the API (Phase 1) and then the addition of concurrent operations (Phase 2).
The first deliverable will be a serialization of the API suitable for use in a multi-threaded application but which doesn't provide any level of concurrency. This step will provide a foundation upon which subsequent deliverables will build as well as being a basis of comparison. Single-thread tests will compare this deliverable with the serial version of the library to establish function call overhead while multi-threaded tests will show how progressively finer-grained locking benefits execution times.
Each global ADT which is currently implemented with several global variables (all ending with _g) will be encapsulate into a single C struct to document the fact that the collection is a single abstract data type. This has already been completed for the data type conversion tables:
|
static size_t nused_g=0; /*number of slots used*/ static size_t nalloc_g=0; /*number of slots allocated*/ static H5T_path_t **path_g=NULL; /*ptrs to conversion paths*/ |
|
New Code: |
static struct {
pthread_mutex_t mutex;
size_t nused;
size_t nalloc;
H5T_path_t **path;
} H5T_g = {
PTHREAD_MUTEX_INITIALIZER,
0, 0, NULL
}; |
Thread initialization happens automatically the first time a thread calls an HDF5 function. This is similar to the way the process-global data is initialized in the serial version of the library and would rely on pthread_once() and pthread_key_create() being called from the FUNC_ENTER() macro. POSIX.1c guarantees at least 128 key/value pairs per process and HDF5 would use at most one per interface (currently 58) with a more likely usage of 10 to 15 (one for each interface that has thread-specific data). Using one thread-specific key/value pair is possible but would increase contention for the interface initialization mutex variables and increase the complexity of the library.
The first call to an HDF5 function (with a few exceptions) causes H5open() to be called to initialize data structures in each package. When H5close() is called (explicitly or implicitly by program exit) all open objects are closed, resources are freed, and global data structures are set to their initial values. These actions are performed for all API functions by the FUNC_ENTER() and FUNC_LEAVE() macros.
Serialization of the API functions will be controlled by a global mutex variable manipulated by the FUNC_ENTER() and FUNC_LEAVE() macros:
|
Basic H5_g: |
struct {
pthread_mutex_t init_m; /*API entrance mutex*/
hbool_t libinit; /*has H5_init_library() been called?*/
} H5_g; |
|
Basic FUNC_ENTER(): |
if (H5_IS_API()) {
pthread_mutex_lock(&H5_g.init_m);
if (!H5_g.init) H5_init_library();
} |
|
Basic FUNC_LEAVE(): |
if (H5_IS_API()) {
pthread_mutex_unlock(&H5_g.init_m);
} |
The first deliverable will provide a library that can be used safely in a multi-threaded application, but in order to be truly useful it must provide some level of concurrency. The largest concurrency payoff is for functions that typically take the longest to execute: H5Dwrite(), H5Dread(), and H5Tconvert(). The second deliverable will allow concurrent operation among these functions but will serialize all other API functions with respect to each other and with respect to these three functions.
As before, the serialization will be controlled by the FUNC_ENTER() and FUNC_LEAVE() macros. However, a second global mutex and condition variable will keep track of how many threads are executing in one of the three expensive functions (these three functions will define a local variable H5_allow_concurrent_g with a non-zero value to override the global variable of the same name and zero value).
|
Basic API_g: |
Struct {
pthread_mutex_t init_m; /*API entrance mutex*/
hbool_t libinit; /*has H5_init_library() been called?*/
unsigned nthreads; /*num thrds in expensive functions*/
pthread_cond_t nthreads_c; /*signaled when nthreads=0*/
} H5_g; |
|
Basic FUNC_ENTER(): |
if (H5_IS_API()) {
pthread_mutex_lock(&H5_g.init_m);
if (!H5_g.init) H5_init_library();
if (H5_allow_concurrent_g) {
H5_g.nthreads++;
pthread_mutex_unlock(&H5_g.init_m);
} else {
while(H5_api_g.nthreads0) {
pthread_cond_wait(&H5_g.nthreads_c, &H5_g.init_m);
}
}
} |
|
Basic FUNC_LEAVE(): |
if (H5_IS_API()) {
if (H5_allow_concurrent_g) {
pthread_mutex_lock(&H5_g.init_m);
if (0==--H5_g.nthreads)
pthread_cond_signal(&H5_g.nthreads_c);
}
pthread_mutex_unlock(&H5_g.init_m);
} |
Property lists do not need any more protection than that provided by the serialization of the H5P interface because the three expensive functions do not modify property lists.
The H5TB layer provides allocation and deallocation of temporary buffers by maintaining a global doubly-linked list of all buffers. If a request cannot be satisfied from the linked list then a new buffer is created and added to the list. All buffers that are in use are also assigned an identification number from the Interface Abstraction Layer (H5I).
The list of buffers will be protected by a mutex during operations that access or modify the list, but the buffers themselves are not protected.
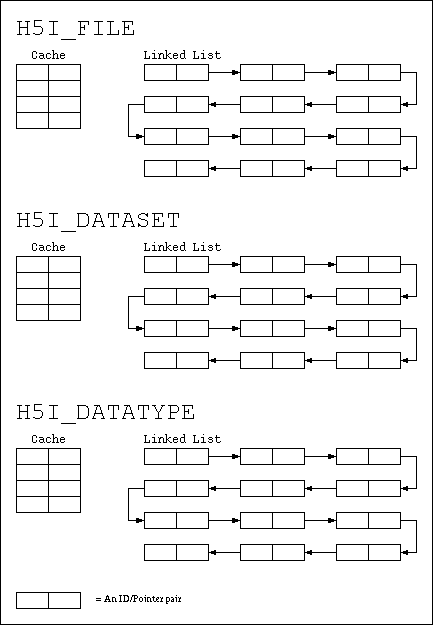
The H5I layer translates object identifiers (hid_t) used by the API into C struct pointers used internally. Each type of object (file, dataset, group, etc.) has its own cache and linked list called an "ID group" (not to be confused with a group used for collecting related objects in a file).
Each ID group will be protected with a mutex because the data type conversion and temporary buffer allocation modifies the ID groups. Testing will indicate whether this is a high-contention lock that needs more work.
The meta data cache is a fixed-length hash table of buckets where each bucket has at most one "inactive entry" and a (usually very small) linked list of "active entries". The other layers of the library check out meta data objects (H5AC_protect()), access the object directly, and then check it back in (H5AC_unprotect()).
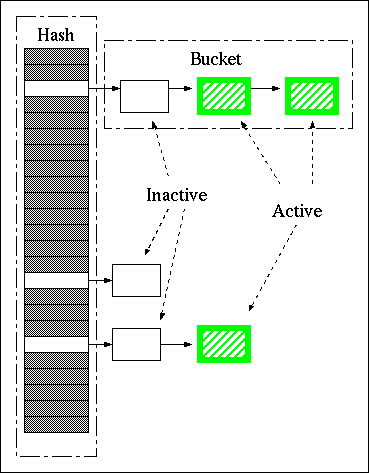
The main hash table does not need to be protected by a mutex because buckets will never change positions. However, each bucket will be protected by a condition variable and a thread will block on the condition variable if the requested meta data object is already locked. The condition variable is signaled when the object is moved from the active state to the inactive state. When a thread needs to activate multiple objects the activation will be in a well defined order to prevent deadlock. Multiple activation currently only happens with B-tree nodes, which are activated from the top down and deactivated in the reverse order.
Reading from and writing to the object header is serialized by the meta data cache (H5AC) so no mutex is necessary in the H5O interface.
This table contains type conversion functions registered by the library and/or the application and is consulted (and possibly modified) during raw data I/O operations and calls to H5Tconvert(). It associates a source and destination data type pair with a pointer to a conversion path structure. The conversion path struct contains conversion statistics, a pointer to a conversion function, and state information needed by the conversion function.
typedef struct H5T_path_t {
mutex_t mutex; /*exclusive access to path */
uintn nrefs; /*number of path references */
char name[H5T_NAMELEN]; /*name for debugging only */
H5T_t *src; /*source data type ID */
H5T_t *dst; /*destination data type ID */
H5T_conv_t func; /*data conversion function */
hbool_t is_hard; /*is it a hard function? */
H5T_stats_t stats; /*statistics for the conversion*/
H5T_bkg_t need_bkg; /*is the background buf needed?*/
void *priv; /*optional app-level data */
} H5T_path_t; |
Each path will have a mutex to protect all struct members. However, private data allocated by the conversion function and pointed to by priv will not be protected. Instead, the conversion function shall create a mutex as part of its private data if necessary. The private data shall be allocated by the conversion function only during the conversion initialization command during which time the path will be locked for exclusive access. The need_bkg value is also computed at that time.
The cdata member (not shown above) which currently is used to pass the conversion command, background buffer status, private data status, and future information will be allocated on the stack instead of stored in the path data structure.
The src and dst path members are copies of the source and destination data types that were passed to H5Tregister() -- they are only pointed to by a single H5T_path_t instance, so locking the path is sufficient for accessing these two data type objects.
Each path will also have a reference count (protected by the path mutex) and the path will only be freed when the reference count becomes zero. The H5T_path_find() function will be split into two parts: H5T_path_lock() will contain most of the original H5T_path_find() functionality but will also increment the reference count, and H5T_path_unlock() will decrement the reference count and free the path when the value becomes zero.
All other members of the path structure are constant and do not need to be protected by a mutex for reading as long as the reference count can be guaranteed to be positive.
Because a conversion may take a substantial amount of time, conversions are designed to run concurrently. The H5T_convert() function will contain the following code:
path = H5T_path_lock(NULL,src,dst,NULL,NULL); path-nrefs++; /*conversion in progress*/ H5T_path_unlock(path); /* ... call the conversion function ... */ H5T_path_lock(path,NULL,NULL,NULL,NULL); Path-nrefs--; /*conversion is finished*/ H5T_path_unlock(path); |
The path table will be protected by a mutex during the binary search of the table for readers or during an entire insertion operation for writers.
Data space conversions use a combination of three tables to associate a source and destination data space pair with a set of conversion functions and statistics accumulators.
The H5S_mconv_g and H5S_fconv_g tables store scatter and gather functions for a single data space between memory and type conversion buffer, and type conversion buffer and file. Currently, they are initialized with constant data when the H5S interface is initialized, although future plans allow for application-defined data space conversions. If the MT-safe implementation occurs before application defined data spaces then these tables will be protected with a mutex around the table check-and-initialize critical section.
The H5S_conv_g table stores associates between a source and destination data space pair and a pointer to a conversion path C struct that contains pointers to optional scatter-scatter functions (used in the absence of data type conversion) and statistics accumulators. The table itself will be protected by a mutex.
Each conversion path struct will be reference counted as with the data type path structs described above and a mutex will protect the critical section that updates the statistics. When application defined data space conversions are implemented there will likely be application defined conversion state information whose protection will also be implemented by the application as with data type conversions.
This is a hash table stored in the H5F_file_t struct (the shared part of a file) with at most one chunk per bucket. In order for multiple threads to access the same chunk concurrently each bucket is protected by a mutex, a reference count, and a condition variable. The hash table itself is not protected by a mutex because its size never changes. To check out a chunk:
To check in a chunk:
A file is actually a three-part data structure consisting of file handles, some of which may point to a shared H5F_file_t struct, which in turn points to a low-level file driver. The file driver is usually a single struct but may be more complicated (the split and family drivers have additional pointers in the file driver struct).
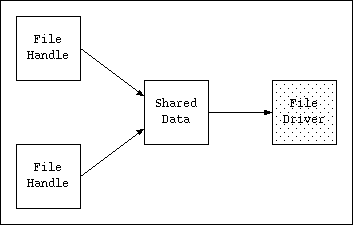
All three parts will contain their own mutex.
Each file maintains a linked list of recently freed blocks of file address space. The list will be protected by the file mutex because the H5Dwrite() performs file memory allocation and deallocation.
The HDF5 error stack is a snapshot of the function call stack for functions within the HDF5 library taken when an error is detected. The stack can be printed automatically just before an HDF5 API function returns failure, it can be passed to an application defined function for error reporting, it can be saved for later use, or it can be discarded. Each thread has its own function stack and therefore needs its own error stack.
Automatic error reporting is set with the H5Eset_auto() function and determines how errors are reported by the library. The H5E_BEGIN_TRY and H5E_END_TRY macro pair temporarily turns off automatic error reporting on a per-thread basis by calling H5Eset_auto().
The H5Fflush() function flushes all cached data to a file, making the file consistent for other tools to read. The file is guaranteed to remain consistent only as long as other tools open the file for read only and the writer application does not perform modifications to any file data structures.
In this implementation of thread safety the flush will operate in the normal manner, flushing all data to the file. However, in order for the application to know exactly when the file is consistent it is necessary for the application's threads to communicate with some kind of barrier. If there is no communication then the flushing thread cannot be sure that all writer threads are finished (at least for a while) and there is a race condition where the flusher's result can be immediately overwritten by some other thread.
If there is no synchronization between the threads then another potential problem exists: the flushing thread can be blocked indefinitely while other threads read, write, or convert data types. This is called starvation of the flush and arises because the convoy effect of reads, writes, and data conversions. These three operations are allowed to start as long as these are also the only operations in progress. With the correct timings it's possible for three threads to keep the library busy enough that the flush operation is delayed. The hdf5 library will not concern itself with starvation of the flush operation because of the inherent race condition that also arises when starvation is possible.
Any function which is not H5Dread(), H5Dwrite(), or H5Tconvert() can experience starvation. The initial implementation will not attempt to remedy the situation but if it proves to be a significant problem then the FUNC_ENTER() and FUNC_LEAVE() macros can be rewritten so that a potentially starved function interrupts the convoy of reads, writes, and type conversions that would cause the starvation.
The second deliverable allowed three expensive functions and their underlying support functions to be run concurrently while restricting the rest of the HDF5 API to be serialized with a coarse-grained mutex locked by FUNC_ENTER() and unlocked by FUNC_LEAVE(). The third deliverable will replace all coarse-grain function locking with finer-grained object locking. In other words, all functions can be called concurrently and those that operate on a common object will be serialized with respect to one another but not with respect to functions operating on other objects.
This section is not complete.
These macros will be modified so that an API function does not lock the H5_g.init_m macro for the duration of the function. Furthermore, the H5_init_library() call is made outside the mutex lock, allowing all internal functions to proceed without obtaining a lock.
|
Basic FUNC_ENTER(): |
if (H5_IS_API()) {
pthread_mutex_lock(&H5_g.nthreads_m);
H5_nthreads_g++;
pthread_mutex_unlock(&H5_g.nthreads_m);
}
if (!H5_g.init) H5_init_library(); |
|
Basic FUNC_LEAVE(): |
if (H5_IS_API()) {
pthread_mutex_lock(&H5_g.nthreads_m);
if (0==--H5_g.nthreads) {
pthread_cond_signal(&H5_g.nthreads_c);
}
pthread_mutex_unlock(&H5_g.nthreads_m);
} |
Since the H5_g.init was checked outside a mutex it is possible that H5_init_library() is already called and shouldn't be called a second time. This is checked with code inside H5T_init_library():
|
Basic H5_init_library(): |
pthread_mutex_lock(&H5_g.init_m);
if (!H5_g.init) {
... initialization ...
H5_g.init = TRUE;
}
pthread_mutex_unlock(&H5_g.init_m); |
|
Basic H5_term_library(): |
pthread_mutex_lock(&H5_g.init_m);
if (H5_g.init) {
pthread_mutex_lock(&H5_g.nthreads_m);
while (H5_g.nthreads0) {
pthread_cond_wait(&H5_g.nthreads_c, &H5_g.nthreads_m);
}
H5_g.init = FALSE;
pthread_mutex_unlock(&H5_g.nthreads_m);
....
}
pthread_mutex_unlock(&H5_g.init_m); |
Because a mutex is used to lock the library initialization and termination functions it is possible that all threads but one will perform busy waiting for many thousand instructions. However, this is normally a one-time situation and the mutex will provide extremely fast checking for entrance and exit for all subsequent calls to the API.
This is a sorted list of "isa" functions that are invoked to determine if an object is a certain type. The list is currently initialized once when the library starts, but there are plans to allow the application to modify the table by adding/removing application-defined "isa" functions. The first MT-safe implementation will deal with one-time table initialization -- if the application is later allowed access to the table then it will have to be protected in some way.
The global filter table is an array of structs that contain information about each filter. This will be changed to be similar to the data type and data space tables by making it an array of pointers to filter structs, each with a reference count and mutex variable. The mutex protects the reference count and other filter state information such as statistics. Two new functions will allow the filter struct to be checked out and checked in by each thread that uses it.
The global heap is implemented as a cache or recently used collections where each collection contains some number of locality-related objects stored in the global heap. A new object can be added to the heap with H5HG_insert() and an existing object can be read with H5HG_read(). The current method of modifying an object is to get a pointer to the object with H5HG_peek() and modifying the memory directly, but this is not suitable for multi-thread safety. Instead, we will get rid of the H5HG_peek() and replace it with H5HG_write() which copies an entire object into the heap data structure.
The list of recently-used heap collections will be protected by the file mutex.
The mount table determines what files are mounted on the parent file and will be protected by the file mutex.
Most confidence testing will consist of long-running semi-random tests using many threads to exercise as many thread interactions as possible. The same tests will be distributed with hdf5 but will run only a few seconds each.
Testing will be performed by the hdf5 team on each platform officially supported using available debugging tools.
HDF-5 and parallel HDF5:
HDF5 web page: http://hdf.ncsa.uiuc.edu/HDF5/
Parallel HDF5 design: http://hdf.ncsa.uiuc.edu/HDF5/doc/ph5design.html
Parallel processing and threads:
Hank Dietz' Linux Parallel Processing HOWTO.
"Practical Unix Programming: A Guide to Concurrency, Communication, and Multithreading", by Kay A Robbins and Steven Robbins. ISBN 0-13-443706-3
"Unix Network Programming" by W. Richard Stevens. ISBN 0-13-490012-X
The Linux Pthreads source code.
"Posix Programmer's Guide: Writing Portable Unix Programs", by Donald Lewine. ISBN0-937175-73-0
MPI and MPI-I/O:
MPI-2 Forum web page: http://www.mpi-forum.org/
Robb Matzke/Robert McGrath/Mike Folk