Collective I/O on chunked datasets can be performed either as a fully collective I/O operation on all the chunks at once (“linked-chunk I/O”), or partially collective, with collective I/O on each chunk individually (“multi-chunk I/O”). The general flowchart for this decision making looks like this:
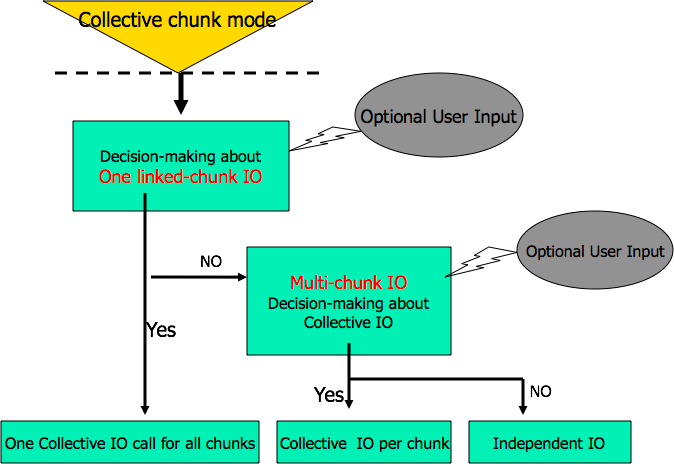
The user input for this algorithm is provided with the following API routines which set properties on a dataset transfer property list (DXPL) that can be used in a call to H5Dread or H5Dwrite.
- H5Pset_dxpl_mpio_chunk_opt() [in src/H5FDmpio.c]
- Set the type of collective chunk I/O to perform (linked-chunk or multi-chunk I/O) without using MPI communication for making decisions.
- H5Pset_dxpl_mpio_chunk_opt_num() [in src/H5FDmpio.c]
- Sets a threshold number of chunks per process for doing linked chunk I/O. The library will calculate the average number of chunks selected by each process. If the number is greater than the threshold set by the application, the library will do linked-chunk I/O; otherwise, I/O will be done for every chunk.
- H5Pset_dxpl_mpio_chunk_opt_ratio() [in src/H5FDmpio.c]
- Sets a threshold for doing collective I/O for each chunk. The library will calculate the percentage of the number of process holding selections at each chunk. If that percentage of number of processes in the individual chunk is greater than the threshold set by the user, the library will do collective chunk I/O for this chunk; otherwise, independent I/O will be done for this chunk.
Describing this in pseudo-code: (source code is in H5D_chunk_collective_io() in src/H5Dmpio.c)
- <check if chunk I/O mode has been chosen with H5Pset_dxpl_mpio_chunk_opt()>
- <set chunk I/O mode from DXPL>
- <else> [chunk I/O mode has not been specified by the application]
- <call H5D_mpio_get_sum_chunk()>
- <get the number of chunks on each process>
- <sum the number of chunks on all processes with MPI_Allreduce()>
- <retrieve the threshold number of chunks per process from the DXPL and compare to the average number of chunks per process>
- <if average number of chunks per process is >= threshold number of chunks per process>
- <set chunk I/O mode to linked-chunk I/O>
- <else>
- <set chunk I/O mode to multi-chunk I/O>
- <if chunk I/O mode is linked-chunk I/O>
- <call H5D_link_chunk_collective_io() in src/H5Dmpio.c> to create the MPI datatype describing all the I/O to all the chunks and perform the I/O>
- <if the dataset only has one chunk>
- <treat the chunk as if it was the block of elements for a contiguous storage dataset>
- <set up MPI datatype for selection in the file and in memory>
- <pass the MPI datatypes down to the MPI-IO VFD, where the collective I/O operation occurs>
- <else> [the dataset has more than one chunk]
- <determine the number of chunks that this process will perform I/O on>
- <if the number of chunks that this node will perform I/O on is greater than 0 >
- <call H5D_sort_chunk() in src/H5Dmpio.c to create an array of the chunks to perform I/O on, sorted in increasing order by the chunk’s address in the file>
- <if the number of chunks per process is > 30% of all the chunks in the dataset and the average number of chunks per process is > 10,000>
- <iterate over all the chunks in the dataset with process 0, retrieving the address of each chunk>
- <use MPI_Bcast() to send the chunk addresses to all the other processes>
- <iterate over all the chunks for this process>
- <retrieve the chunk’s address (if we don’t already have it)>
- <set up chunk I/O information and chunk address in array to sort>
- <sort the array of chunk I/O information in increasing chunk address order>
- <iterate over all chunks for this process>
- <create an MPI datatype for the memory and file selection for each chunk, according to the algorithms defined for each selection type in Collective I/O on Contiguous Datasets>
- <store the MPI datatype for the memory and file selection in array>
- <use MPI_Type_struct() and MPI_Type_commit() to create single final MPI datatype for all chunks in the file>
- <use MPI_Type_struct() and MPI_Type_commit() to create single final MPI datatype for all chunks in memory>
- <release all intermediate MPI datatypes for individual chunks>
- <set the MPI count to 1>
- <call H5D_final_collective_io() (in src/H5Dmpio.c) to perform the final call
- <else> [this process has no chunks to perform I/O on]
- <set the file and memory MPI datatype to MPI_BYTE and the MPI count to 0>
- <call H5D_final_collective_io() (in src/H5Dmpio.c) to perform the final call to perform the collective I/O operations in the MPI-IO VFD>
- <else if chunk I/O mode is multi-chunk I/O> [i.e. the application requested collective I/O on as many chunks as possible]
- <call H5D_multi_chunk_collective_io_no_opt() (in src/H5Dmpio.c) to perform I/O on chunks>
- <call H5D_mpio_get_min_chunk() (in src/H5Dmpio.c) to determine the minimum number of chunks, <max_coll_chunks> to perform I/O on, for all chunks>
- <each process determines the number of chunks it will perform I/O on>
- <use MPI_Allreduce() with MPI_MIN on the number of chunks for each process to generate the number of chunks that collective I/O can be used for>
- <iterate over chunks for this process, tracking the index of the chunk we are operating on in <chunk_index> >
- <if <chunk_index> is greater than <max_coll_chunks> > [need to perform independent I/O on this chunk]
- <write data elements to disk using single I/O operation for each run of contiguous elements in the chunk> [i.e. like serial I/O on the chunk, but don’t pull the chunk into the chunk cache]
- <else> [perform collective I/O on this chunk]
- <call H5D_inter_collective_io() (in src/H5Dmpio.c) to create MPI datatype for file and memory selection and perform I/O>
- <if there’s a file and memory selection>
- <create an MPI datatype for the memory and file selection for chunk, according to the algorithms defined for each selection type in Collective I/O on Contiguous Datasets>
- <call H5D_final_collective_io() (in src/H5Dmpio.c) to perform the final call to perform the collective I/O operations in the MPI-IO VFD>
- <else> [the chunk I/O mode should be determined for each chunk]
- <call H5D_multi_chunk_collective_io() (in src/H5Dmpio.c) to perform I/O on chunks>
- <allocate arrays to hold the type of I/O to perform on each chunk and the address of each chunk>
- <call H5D_obtain_mpio_mode() to obtain the type of I/O and address for each chunk>
- <retrieve the <percent_nproc_per_chunk> value from the DXPL (set with H5Pset_dxpl_mpio_chunk_opt_ratio() ) >
- <if configure-time setting that “complex derived datatypes work” and “special collective I/O works”>
- <if <percent_nproc_per_chunk> is 0 (i.e. always do collective I/O on all chunks) >
- <retrieve the chunk addresses with H5D_chunk_addrmap() (in src/H5Dmpio.c)
- <set the type of I/O for each chunk to “collective”>
- <else> [configure-time settings false or <percent_nproc_per_chunk> greater than 0]
- <allocate <io_mode_info> array of size <total # of chunks> initializing each array element to the “no selection” value >
- <allocate <recv_io_mode_info> array of size (<# of MPI processes> * <total # of chunks> >
- <iterate through all the chunks selected for this process>
- <if the file and memory selection are regular>
- <set the <io_mode_info> for this chunk to “regular”>
- <else> [the file or the memory selection is irregular>
- <set the <io_mode_info> for this chunk to “irregular”>
- <use MPI_Gather() to send each process’ <io_mode_info> array to process 0, which receives them in the <recv_io_mode_info> array>
- <if process is rank 0>
- <call H5D_chunk_addrmap() (in src/H5Dmpio.c) to retrieve the chunk addresses>
- <iterate over the number of processes>
- <iterate over the total number of chunks in the dataset>
- <if the current process will perform I/O on this chunk>
- <increment the number of processes that will perform I/O on the chunk>
- <iterate over the total number of chunks in the dataset>
- <if the number of processes that will perform I/O on this chunk is greater than <percent_nproc_per_chunk> >
- <set the I/O mode for this chunk to “collective”>
- <use MPI_Bcast to broadcast the I/O mode and address of each chunk to all processes>
- <iterate over all chunks for dataset>
- <if collective I/O for this chunk>
- <if this process will perform I/O on this chunk>
- <set the file and memory dataspace to the description for this chunk>
- <else> [this process doesn’t have any I/O for this chunk]
- <set the file and memory dataspace to NULL>
- <call H5D_inter_collective_io() (in src/H5Dmpio.c) to perform the I/O (covered earlier in this page) >
- <else> [independent I/O for this chunk (possibly) ]
- <if configure-time check for “complex derived datatype works” or “special collective I/O works” failed> [need to perform independent I/O on this chunk]
- <write data elements to disk using single I/O operation for each run of contiguous elements in the chunk> [i.e. like serial I/O on the chunk, but don’t pull the chunk into the chunk cache]
- <else> [possible to perform independent I/O using MPI derived datatype]
- <set the I/O mode in the DXPL to perform independent I/O, but use a derived datatype (i.e. call MPI_FIle_set_view in read or write MPI-IO VFD callback)>
- <if this process will perform I/O on this chunk>
- <set the file and memory dataspace to the description for this chunk>
- <else> [this process doesn’t have any I/O for this chunk]
- <set the file and memory dataspace to NULL>
- <call H5D_inter_collective_io() (in src/H5Dmpio.c) to perform the I/O (covered earlier in this page) >