It
seems to me that three over-arching notions appear in the use case doc you sent
me:
- testing the
correctness of the library,
- measuring the
library’s performance in time (i.e., speed), and
- measuring the
library’s performance in space.
Let’s
focus first on measuring performance, since that’s the principle focus of this
project. Let’s assume that we measure
speed with some sort of “timer” and spatial usage with some sort of disk and
memory “rulers” and that we measure all aspects of performance in every test.
Then
I claim that all performance tests follow one of two basic patterns:
- the basic pattern (complete
i/o):
define the source of a data transfer
define the destination of a data transfer
define the transfer process
start performance measurement
H5Dwrite() or H5Dread()
stop performance measurement
cleanup
Suppose that we have a device, an iterator, that
synchronizes stepping through the source and destination dataspaces. Then the partial i/o pattern is:
- the iterated pattern (sequential
partial i/o):
for (iterator_start; ! iterator_is_done;
iterator_next)
{
basic pattern
}
Note
that the basic pattern is a special case of the iterated pattern – a single
iteration. The definitions of the
source, destination, and process of data transfer cover the definitions of the
datatype transferred, the dataspaces in memory and on disk, the selections on
these dataspaces, any sequence of filters applied to the data in transit, any
special properties of the source, destination, and transfer, the number and topology
of processors participating in the transfer, etc. Here’s a list of all the “actors” defining
the source, destination, and transfer:
|
Actor |
Representation |
Implementation |
|
memory
buffer |
contiguous
array of bytes |
Wrapper
around malloc() |
|
memory
dataspace |
hid_t |
HDF5
library |
|
memory
selection |
Private
to HDF5 library |
HDF5
library |
|
memory
datatype |
hid_t |
HDF5
library |
|
file |
hid_t |
HDF5
library |
|
dataset |
hid_t |
HDF5
library |
|
disk
dataspace |
hid_t |
HDF5
library |
|
disk
selection |
Private
to HDF5 library |
HDF5
library |
|
disk
datatype |
hid_t |
HDF5
library |
|
file
creation properties |
hid_t |
HDF5
library |
|
dataset
creation properties |
hid_t |
HDF5
library |
|
process
set and topology |
MPI_Comm |
MPI
library |
|
filter |
Private
to HDF5 library |
HDF5
library (or user code?) |
|
transfer
properties |
hid_t |
HDF5
library |
|
timer |
double |
MPI_Wtime()
or getrusage() system call |
|
memory
ruler |
double |
? |
|
disk
ruler |
double |
stat()
system call |
Any
HDF5 performance test can be constructed by selecting one particular implementation
of each of the actors and one particular implementation of the iterator and somehow
sticking these choices together to form an executable. The number of different tests one can
construct with this assembly process is staggering. As a crude illustration, let’s say we have n different actors, each of which comes
in m varieties. Then there are mn different ways we can combine the actors. Just to play with numbers, and not taking the
numbers too seriously, note that 18 different actors are listed above. If each has 2 different implementations,
i.e., 2 different kinds of dataspaces, 2 different kinds of selections on
dataspaces, 2 different kinds of datatypes, etc., then there are 218
or about a quarter of a million different kinds of tests we can construct.
The
second claim I make is that our test suite should be capable of instantiating
any possible test. We clearly won’t
instantiate all possible tests – there are simply too many – but we should not
build a test suite in which some kinds of tests can’t be performed. Experience tells us that the test we can’t
perform will be precisely the test we need to perform.
There
may be mn possible tests,
but fortunately there are only m*n actors
that we might have to implement. To
continue playing with example numbers, the quarter million possible tests we
calculated above can all be constructed out of 2*18 = 36 different actors. 36 is a very manageable number. This result suggests that every test in our
test suite be built by combining pre-existing components into distinct
arrangements. The task of building a
test suite is really a task of building machinery to make new combinations of
existing components.
Now
let’s see if we can exploit any structure that might exist in the set of all
possible tests, with the hope that such exploitation would make it easier to
construct specific tests. But first,
let’s illustrate the structure with an example.
Suppose that out of the set of all possible tests we focus on tests
constructed out of components a, b, and c. a might be a particular kind of dataspace, b might be a particular datatype, and c might be a particular kind of filter. (But a,
b, and c can be any particular implementation of any of the actors we
listed above.) Then the set of all tests
that use component a is some subset
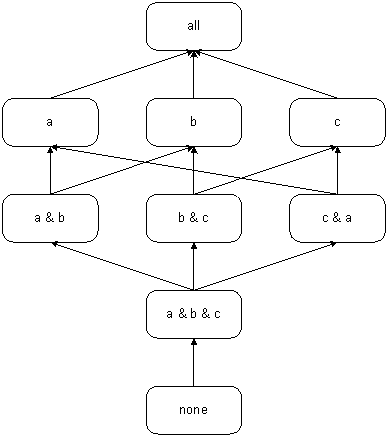
of all possible tests, and likewise with components b and c. In the diagram below, sets and subsets are
indicated with boxes. The labels
indicate the contents of the set. An
arrow from one box to another indicates that the first set is a subset of the
second. So the tests using components a, b,
and c form a subset of the tests
using only components a and b, and that set is in turn a subset of
those tests using only component a. What is notable about this diagram is that it
is precisely an inheritance diagram. If
we were to implement the test suite in an object-oriented manner using
inheritance, and if we drew its inheritance diagram, we’d get exactly the same
diagram. In general, the set of all
possible HDF5 tests has the structure of an inheritance hierarchy.
From
this result, we conclude that the natural way to implement the test suite is
with an object-oriented language using inheritance.
But
let’s examine various ways that the test suite could be constructed. I’ll start with two extreme cases that will
help narrow the focus. The two extreme
cases are:
- a single monolithic
executable covering all possible tests
I picture this as a big piece of code which takes
as input a “test specification language” – something that could describe, for
example, that one particular test uses chunked datasets of a given size, and
2-d dataspaces of which only the first dimension is fixed, and does partial
i/o, uses 8 processors, data compression, and a user defined datatype
containing a mixure of ints, doubles, and chars.
Clearly, a “test specification language” to
describe anything that HDF5 can do would be exceedingly complex, and the
machinery to parse it and handle all the myriad cases would be more
complex. Apart from the difficulty of
constructing such a beast, we’d need a test suite to test the tester.
- one single purpose
executable per test
At this extreme we’d write a precisely focused
piece of code for each test variation – something that does only what is
required for a specific test case, and no more.
This approach has the virtues of simplicity and understandability. It’s also compatible with the conclusion
reached above that we should construct tests out of pre-existing components.
So,
now we’ve argued ourselves into the position that each test should be a small
piece of software that is focused on a single situation, that we should build
tests out of pre-existing components (implementations of the actors tabulated
above), and that using inheritance is a natural and powerful way to construct
new test cases from old ones.
How
might we construct such test suites in C++, C, and F90?
- C++
Implementing the test suite in C++ is easy and
natural because the language is designed specifically to express the
hierarchies of similarities and differences inherent in the proposed test
suite. One could start with an abstract
use case class (a “root” class) that defines but does not implement what every
use case should do. The root class would
be equipped with an interface enabling it to fit into an automated test
harness. Each test in the test suite
would be a concrete descendant of the root class, i.e., a descendant that
implements the entire abstract interface introduced in the root class. A layered inheritance hierarchy allows a gradual
introduction of various specializations: complicated user defined datatypes,
different kinds of dataspaces, extendible rather than fixed datasets, different
patterns of partial i/o, etc. Gradual
layering provides abundant opportunities for specialization and makes it easy
to express any specific specialization with very little code. We used this technique extensively and
effectively at LPS.
- C
I can think of several ways of constructing the
test suite in C:
- Emulate C++
C is a procedural language, not an object oriented
language, so expressing the object-oriented notions of inheritance and
polymorphism is not a natural thing to do in C.
But it can be done. http://www.embedded.com/97/fe29712.htm and http://ldeniau.home.cern.ch/ldeniau/html/oopc/oopc.html
give similar detailed accounts of the techniques
involved.
Briefly, one uses a struct to encapsulate the data
representation of a class. A descendant
class’s struct
always installs the immediate ancestor’s struct as its first data member. Then the construct
((ancestor*)&descendant)-> properly accesses the ancestor’s struct data
members. Methods that are meant to be
redefined in descendant classes are referred to by a function pointer stored as
class data. Descendant classes can
initialize this pointer to a different function from the ancestor class,
thereby specializing ancestor class behavior.
Essentially, one can do in C what is done in C++ if
one is willing to do by hand tasks that the C++ compiler does automatically,
and if one is willing to forgo C++ compiler benefits such as type checking.
- Copy-and-tweak
One could just program each test case individually,
copying similar bits and pieces from other tests and tweaking these bits and
pieces so that they work together.
This is certainly a simple technique, and has the
benefit that all the code to an example is in one place, where it can be
comprehended as a whole. Since we
advocate using a minimalist coding style – one test focusing exclusively on one
use case – each test should be easy to understand as well. However, experience warns that writing lots
of customized code is error prone and hard to maintain.
- Build a source
“library”
A variation on “copy-and-tweak” is to #include
existing source code into a new test case rather than copying it with an
editor. One can imagine writing a number
of C functions that create numerous variations on the actors tabulated above,
and C functions that specify various kinds of iterators and behavior
patterns. Then a specific test could be
constructed by #including one’s choice of actors and behaviors. This approach requires that the C functions
conform to a pattern so that no editing is required after inclusion. But that’s just good software engineering
practice.
The source library approach makes it easier to
maintain code than copy-and-tweak, because there’s only one copy of each bit of
code. Fixes to this one copy propagate
automatically to all clients. One
drawback to this approach is that there may be quite a number of these bits of
source code; one needs some scheme for browsing them to find one that fits the
current need. Another drawback is more
subtle. Suppose you wanted to use a
certain dataspace definition as both the source and destination
dataspaces. Would one #include it twice,
once for the source and once for the destination? Wouldn’t that result in a redefinition
compilation error? One could solve this
problem by having separate source libraries for source and destination
dataspaces (and datatypes, and selections, and …) with different interfaces and
#including the common definition of this dataspace into both the source and
destination versions. This “solution” sounds
clumsy; one worries about what other unidentified problems are lurking in this
approach.
- Build a
traditional object library
One can imagine building a pre-compiled object
library of useful actors and behaviors, then writing short programs that link
code from this library. At first glance
this approach seems to be an obvious improvement on the “source library”
idea. However, there’s a substantial
difficulty in building such a library: name clashes. We’d like to be able to program behavioral
patterns once, and have these patterns call test specific actions. In object-oriented terminology, we want polymorphism. An object-oriented language like C++ supports
multiple implementations of a named feature by uniquely mangling the source
name when it produces object code, and demangling at link time. So, to support polymorphism in a C object
library, we’d have to come up with a name mangling scheme. Note that the “source library” name
redefinition problem is just the name mangling problem arising in a different
way.
- F90
For the purposes of this project, it appears that
F90 and C allow more or less the same implementation approaches:
- Emulate C++
I found two good papers that discuss object
oriented programming in F90: “How to Support Inheritance and Run-Time Polymorphism
in Fortran 90”, and “How to Express C++ Concepts in Fortran 90”, both by Decyk,
Norton, and Szymanski, and available at http://www.cs.rpi.edu/~szymansk/oof90.html.
I won’t try to describe the techniques because I’m
not fluent in F90. See the papers cited
for the details. However, the F90
techniques give the impression of being something like the C techniques for
emulating C++. The good news for F90 is
that inheritance and polymorphism is possible with about the same effort as in
C. The bad news is the same as it is in
C: one has to do by hand tasks that are done automatically by an
object-oriented compiler.
- Copy-and-tweak
This is the same technique as discussed above with C,
with the same pros and cons.
- Build a source
“library”
F90 appears to have an include directive, so this is
the same technique as discussed above with C, with the same pros and cons.
- Build a
traditional object library
Without knowing F90 better than I do, I suspect that
the name mangling/demangling issue identified in the C discussion also arises
in F90.
Language Summary
A test suite has an inherent hierarchical structure. C++ can express this hierarchy in a simple
and natural way using its native language constructs. C and F90 can also express this hierarchy,
but awkwardly, with added programmer discipline and effort, using the
techniques described in the references cited above. If one wants to use C or F90 in a more
natural way, then the copy-and-tweak method is probably the most
straightforward approach to take.
So
I recommend using C++.
Arguments
against C++
I’ve
heard three arguments against C++, which I’ll try to address. They are:
- limited or no HDF5
development team C++ experience
From personal experience, I think this is a
non-issue. When I started with LPS, I
had no C++ experience at all. Others at
LPS had at most a cursory knowledge of C++; no one had written anything much
bigger than “hello, world”. Within a
week or two we were all reasonably fluent in basic C++. We all quickly grew to prefer it to C, since
it is so much better at allowing one to package up and reuse understandable
pieces of code. I think that a team of
developers like the HDF5 staff, who know C, F90, XML, autoconf, html, Java,
MPI, all sorts of Unix mini-languages, Macs, Windows, etc. would have little
difficulty in picking up the basics of something that, after all, is a lot like
C.
- maintenance effort
porting to different compilers/platforms
I’ve programmed on a linux platform using g++ and a
commercial compiler that has since become the Intel compiler. I don’t have direct experience with porting
to other platforms. As I recall, the LPS
code was ported to various LLNL and Sandia ASCI machines with little
effort. The biggest problem was telling
the compiler where to find C++’s Standard Template Library (STL) header files,
which tended to be located in various different places on different platforms
and named in slightly different ways, and where to find our own class header
files, which were scattered among a number of directories. Autoconf solved those problems. We coded in ANSI standard C++, which seemed
to be quite portable. I am not aware of
us encountering any of those irritating problems where legal code is rejected
or miscompiled on certain platforms. At
the time we were developing, g++ was undergoing a major revision from its own
dialect of C++ to ANSI standard C++.
Even this caused us little more difficulty than being fastidious about
using std:: to specify the proper namespace for standard C++ library operators. In my experience, C++ requires about the same
maintenance effort as other languages.
The mozilla development team’s recommendations
about C++ portability are found at http://www.mozilla.org/hacking/portable-cpp.html. The only recommendation that sounds
burdensome to me is the fifth in this list: not using C++ standard library
features because including the associated header files is nonportable among
compilers that support different C++ standards.
That’s the problem I mentioned above.
We solved this problem at LPS with autoconf and wrappers.
- small C++ HDF5 user
base; large C and F90 user base
Test suite code could serve other purposes besides
just measuring HDF5 library performance:
- It could serve as a
set of examples to users of how to accomplish tasks in HDF5.
- It could serve as
experimental prototype code that users could run to determine how best to
structure their own codes.
- It could serve to
provide shareable source code examples between users and HDF5 developers,
free of proprietary constraints, and free of code that is extraneous to
technical discussions about HDF5 behavior on client platforms and
problems.
All of these purposes are best served by a test
suite written in a language known well by both the user and the HDF5
development team. C++ isn’t that
language, but C and F90 are.
If we insist that the test suite does double duty, both
measuring performance and serving the purposes listed above, then the test
suite can only be constructed in one way.
We can’t use C++, and we can’t use C or F90 in C++ emulation style,
since those styles are somewhat unnatural for these procedural languages, and
users won’t easily understand examples written this way. The only approach we’re left with is
“copy-and-tweak”. And we have to have
two test suites, one written in C and a duplicate one written in F90. The C users aren’t going to want to look at
F90 code, and the F90 folks won’t want to look at C code.
So neither C++ nor C/F90 do everything we want to
do in a satisfying way. The way out of
this dilemma might be to maintain multiple test suites, one in each
language. Three test suites sounds like
a really bad idea, but it might work better than it sounds:
The C++ test suite would be the largest and most
complete because C++ lends itself better than C/F90 to writing many test cases
easily. The C++ test suite would be
populated systematically with test cases because it would be easy to do so. The C++ test suite would be used principally by
HDF5 library developers interested in maintaining or improving performance. And it could be used when HDF5 is installed
to report the performance of that installation.
The C and F90 test suites would be populated on an
ad hoc basis. Whenever the HDF5
development team engaged in a discussion with a client about some use case,
that use case would be located or coded in the C++ suite. That C++ test would be translated to C or F90
– whichever language appealed to the client – and installed in the appropriate
C or F90 suite. The translation would be
done in a procedural style natural to C or F90, and not in a C++ emulation
style. The translation to C need not be
very complicated – just copy methods out of the C++ inheritance hierarchy, and
edit a bit to glue the methods together.
The C and F90 suites would grow slowly and unevenly, but would consist
of real use cases stripped down to their HDF5 essence. They’d have the same sort of role as code
found in contrib/ directories in many source code distributions: real examples
of how to use the library, but not actively maintained by developers.
Now
let’s switch our focus to testing the library’s correctness:
The
concept of HDF5 correctness divides itself naturally into two parts: the
internal correctness of the library and its external correctness. It divides this way because there's a public
interface available through hdf5.h and private interfaces not accessible
through hdf5.h. Client code
exercises the external, public part and library code exercises the internal,
private part. For all practical
purposes, the public interface allows an infinite number of use cases, so
client code can be unpredictable, and may occasionally push the library's
limits. The private interface, on the
other hand, is probably used in a smaller and more precise and more directed
way. Client code cannot exercise the
private, internal interface for the simple reason that it's inaccessible. Because of these differences, internal and
external interfaces should be tested in different ways.
- Internal Correctness
At LPS, we used a form of Bertrand Meyer's “Design
by Contract” ideas to ensure the correctness of a very large and complicated
application that we built for ASCI on top of HDF5. (More information on DbC is available in “Object
Orient Software Construction”, by Bertrand Meyer, “Design by Contract by
Example”, by Mitchell and McKim, and at Meyer's Eiffel language web site, http://www.eiffel.com/developers/presentations/.)
Briefly, here's how it worked:
The software was divided into “objects”, pieces
that encapsulated a data structure and operators on that datastructure. The operators were of two kinds: queries,
which do not change the state of an object but return information about it, and
commands, which change the state of an object, but return no information about
it. Each operator was equipped with a
“contract”, i.e., a set of preconditions, which the caller guarantees to be
true on entering the operator, and a set of postconditions, which the operator
guarantees to be true on exit. In
addition, each class of objects had an associated invariant, a boolean valued
query which the class guaranteed to be true at every moment when an instance of
the class is accessible to a client. We
implemented the pre and postconditions with C/C++ assert
statements. Since the contracts were
executable, they tested the code every time it was run, and in every path of
execution ever tried. A contract in
executable code is an extremely precise statement of what a routine needs, and
what it does, and what the underlying data structure represents. So, the writing of contracts sharpened the
public and private class interfaces, helped design the software, and tested the
code thoroughly.
Here's what it looks like in a little pseudo-code:
int
some_query(object* obj, other args...)
{
int result;
/* Preconditions */
assert(obj != NULL);
assert(property(obj) == 7);
/* Body of function */
do something that doesn't change the state of
“obj”.
result = whatever;
/* Postconditions */
assert(invariant(obj)); /* state is still valid */
assert(property(obj) == 7); /* state hasn't changed
*/
/* Exit */
return result;
}
This implementation of Design by Contract proved to
be immensely powerful. Once a class was
implemented and went through some initial testing, it just worked correctly
from then on and clients of that class could trust it implicitly. We never experienced the kinds of
intermittent or undefined behaviors that tend to crop up in C. HDF5 is written in procedural style, but it
does have well defined objects, so DbC could be used. Retrofitting HDF5 with Design by Contract may
not be a small undertaking, but in the long run I would expect it to be far
superior to writing a test suite.
- External Correctness
Software contracts should be effective on the
internal interfaces because those interfaces are thoroughly exercised by normal
use of the library. But the external
interface tends not to be used as much by developers, so fitting it with
contracts may not prove its correctness.
Furthermore, developers tend not to abuse it or push its limits. Clients tend to write much more challenging
code, and they are more likely to provide good test cases. So an external interface test suite should be
written and it should definitely contain client written code. However, client code may be proprietary, or
it may contain a lot of complications irrelevant to an HDF5 test. So client written code should be reduced
somehow to its essential HDF5 behavior, and the irrelevant or needlessly
complicated code should be stripped out.
Because there are lots of different ways in which HDF5 can be used, an
external interface test suite should be a large one. A large test suite should be handled by an
automated test harness, so there should be a uniformity to each test – a
conformity to the test harness. And the
test suite should be written in a natural, library supported language: C, C++,
or F90, so that it can express any execution path through the library.
At least two questions arise from having lots of
tests: how do you know which cases
you've actually tested (or, conversely, you haven't tested), and how do you
write and maintain all the test code?
One classic response in computer science to
managing this sort of complexity is to factor out and reuse common
patterns. Let’s elaborate a little on
the basic HDF5 use pattern introduced above:
create_io_environment()
{
define the parallel environment
define file and memory dataspaces and selections
define file and memory datatypes
create a memory buffer
define the dataset characteristics
open/create a file and dataset
optionally define a filter
}
do_io_test()
{
do whatever io action needs testing
}
main()
{
create_io_environment()
do_io_test()
report_results()
}
One can easily imagine running a family of tests in
which this pattern is repeated but the parameters of datatype, dataspace, type
and number of datasets, etc. vary from test to test. While it's easy to make a copy of a source code
file and tweak it slightly for a new variation, the copy-and-tweak methodology
soon becomes a maintenance problem.
Experience suggests that it's much better for constant "stuff"
to be coded once and reused. So, we're
led to consider ideas such as expressed in "Design Patterns: Elements of
Reusable Object-Oriented Software" (Gamma, et. al.) and “Patterns for
Parallel Programming” (Mattson, Sanders, and Massingill). I can see at least three of their "Behavioral
Patterns" that our test suite could profit from:
"Template
Method"
Defines the skeleton of an algorithm, deferring
some steps to subclasses. That's what
do_io_test()) does above.
"Strategy"
Defines a family of algorithms and makes them
interchangeable, letting the algorithm vary from client to client. An example might be using fixed size data
structures and fixed size datasets vs. using extendible data structures and
chunked datasets.
"Iterator"
Provides a way to access the elements of an
aggregate object sequentially w/o exposing the representation of the object. An example of this might be stepping through
memory and disk dataspaces by coordinated changing of selections and extending
a chunked dataset and writing to it at each step. An "iterator" would coordinate the
dataspace selection and dataset extension activities.
Other useful patterns undoubtedly exist, but these
examples alone argue for our "tool" to be coded so that it is easy to
express and reuse such behavioral patterns, to replace one pattern with
another, and to vary the types and properties of the objects that act within
these patterns.
- Speed
Measuring speed is an easy extension to testing
correctness if we have a suitably designed library of usage patterns. For example, the pattern outlined above can
be fitted with a timer. Only the code in
red changes:
create_io_environment()
{
same implementation as above
}
do_io_test()
{
start a timer
do_io_action()
stop the timer
return elapsed time
}
do_io_action()
{
do whatever io action needs a performance test
}
main()
{
create_io_environment()
do_io_test()
report_results()
}
The fact that this performance test example uses
nearly the same code as the external interface test example suggests that if we
design our test suite correctly, we should be able to use any performance test
as an external interface test and vice versa.
The timer can be implemented as a call to
getrusage() in serial and MPI_Wtime in parallel. A good example of this already exists in
XXXX.
- Space
Measuring and resporting the spatial resources
(memory and disk) consumed by a use case ought to be yet another simple
variation on the use case examples shown above.
We time an operation by noting a starting time and a stopping time, and
reporting the difference as the elapsed time used. Measuring the consumption of spatial
resources is not essentially different – just note the starting and stopping
size of memory and/or disk resources and report the difference.
create_io_environment()
{
same implementation as above
}
do_io_test()
{
measure space consumed before i/o
do_io_action()
measure space consumed after i/o
return net increase in space consumed
}
do_io_action()
{
do whatever io action needs a performance test
}
main()
{
create_io_environment()
do_io_test()
report_results()
}
The similarity of this code to the speed testing
code suggests another opportunity for code reuse. Designed correctly, we ought to be able to
slip any measuring instrument into any use case without having to recode the
use case. For speed tests, the
instrument is a “stopwatch”. For space
tests, it's a “ruler” (rulers measure how big something is, right?). For correctness tests, we might have a
“counter” - something that counts the number and severity of unsuccessful
library calls. Or maybe we always
measure all aspects of performance: correctness, speed, and space. The overhead of measuring these
characteristics should be a small fraction of the cost of running the use
case. Why not get every bit of
diagnostic information from every test run?
How do we measure sizes? Stat() call gives the file size on disk. But I haven’t found any portable equivalent
call to determine how much memory a process has consumed. Perhaps HDF5 could keep track of some of this
by wrapping malloc/calloc/free/etc. calls in something that keeps track of the
amount of memory requested. This is at
best a lower bound on the memory used, however.
I wonder how useful that would be?